
Redis
Remote Dictionary Service, 远程字典服务,内存式数据库,非关系型,KV结构
三张网图描述redis基本数据结构:
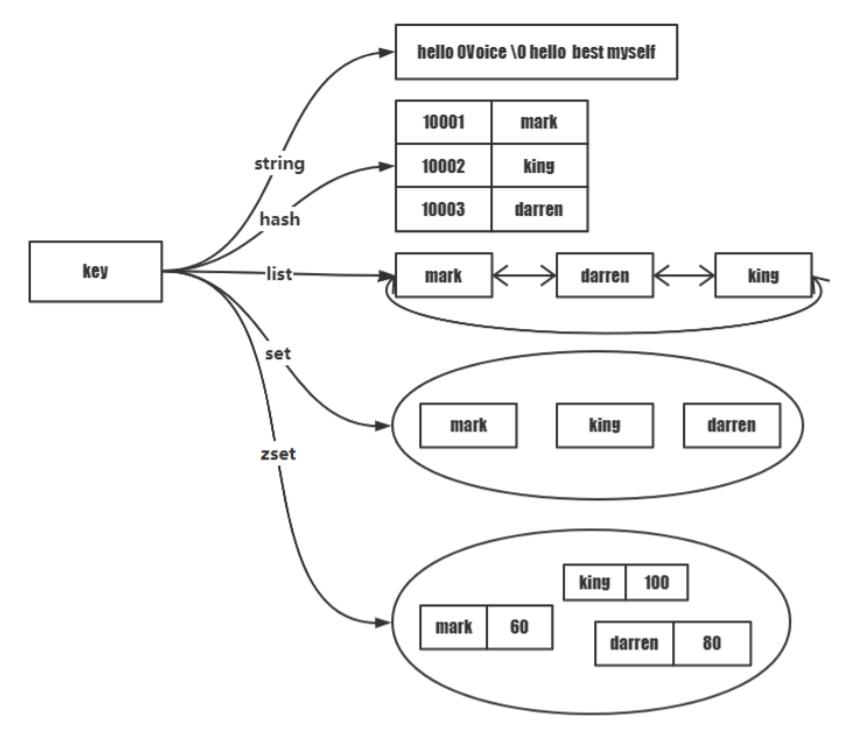
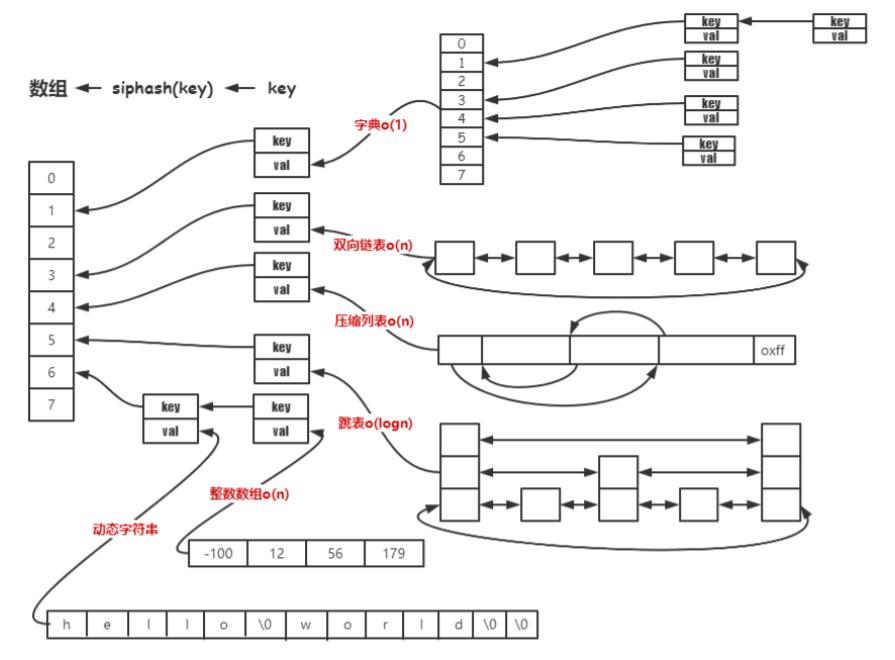
数据与编码
String
字符数组,该字符串是动态字符串,字符串长度小于1M时,加倍扩容;超过1M每次只多扩1M;字符串最大长度为512M;
Tips:redis字符串是二进制安全字符串;可以存储图片,二进制协议等二进制数据;
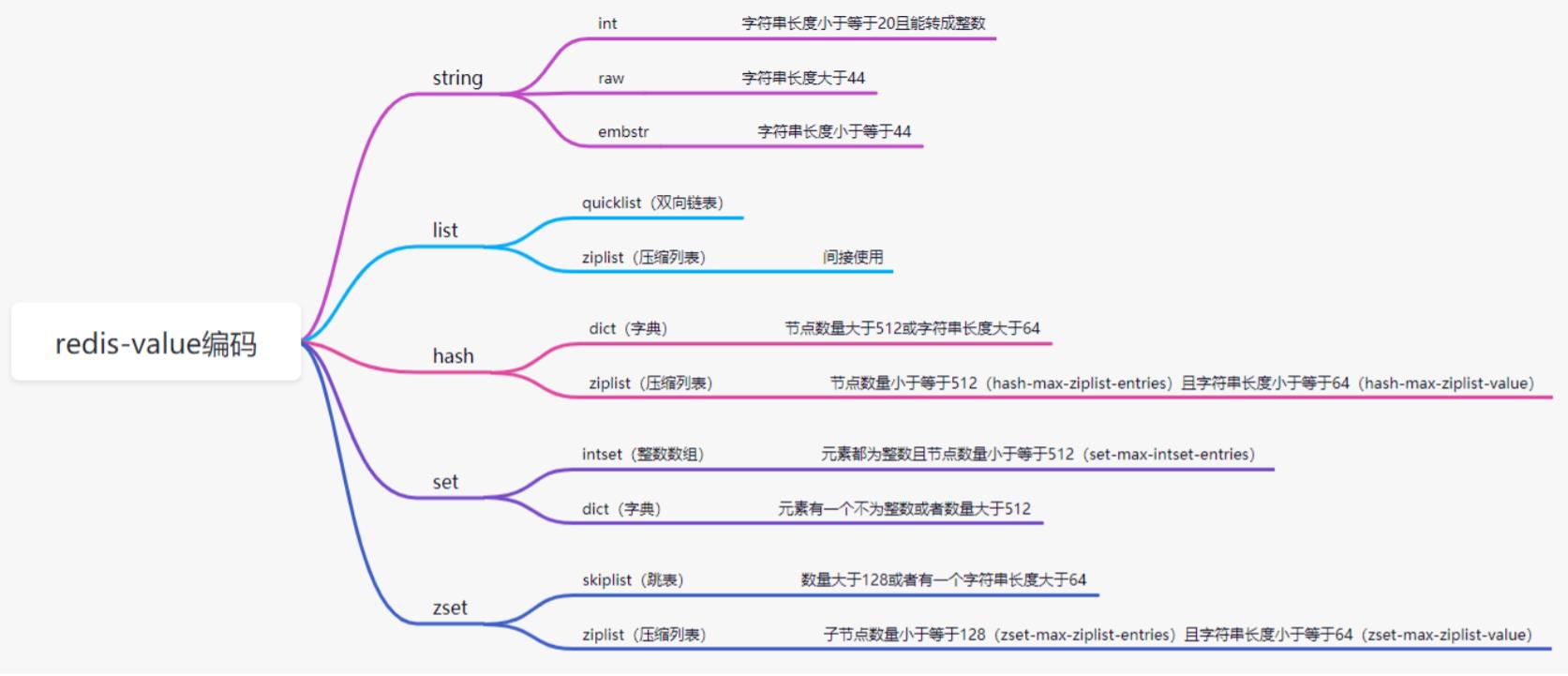
- 字符串长度小于等于 20 且能转成整数,则使用 int 存储;
- 字符串长度小于等于 44,则使用 embstr 存储;
- 字符串长度大于 44,则使用 raw 存储;
44为界
首先说明redis以64字节作为大小结构分界点,但其sdshdr和redisobject结构会占用一些空间,所以真正保存数据的大小小于64字节
旧版本使用39为界,新版本使用44为界,这是因为旧版本中sdshdr占用8字节目前的sdshdr8是针对小结构的优化(大结构使用shshdr16,64),仅占用3字节,节省了5字节空间。所以新版本以44为界。
raw和embstr
raw 编码会调用两次内存分配函数来分别创建 redisObject 结构和 sdshdr 结构, 而 embstr 编码则通过调用一次内存分配函数来分配一块连续的空间存储两结构
embstr使用连续内存,更高效的利用缓存,且一次内存操作带来了更好的创建和销毁效率
操作方式与转换
-
以一个浮点数的value作为例子,浮点数会被转换成字符串然后存储到数据库内。如果要对V进行操作,他也会先从字符串转换为浮点数然后再进行操作。
-
以一个整数2000的value作为例子,该数会被保存为int但使用append进行追加一个字符串“is a good number!”后, 该值会被转换为embstr, 然而embstr的对象从redis视角看来是只读的(未实现操作embstr的方法), 所以该对象又会被转换raw然后实行相应操作并保存为raw
List
双向链表,很容易理解,但其node有讲究(压缩时使用ziplist)
列表中数据是否压缩的依据:
- 元素长度小于 48,不压缩;
- 元素压缩前后长度差不超过 8,不压缩;
直接放数据结构,然后分析:
/* Minimum ziplist size in bytes for attempting compression. */
#define MIN_COMPRESS_BYTES 48
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually <
32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for
usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small*/
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all
ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual
nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to
compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
OK, 可以很明显看到list本身是一个双向链表,但他会记录所有的entry的数目,node本身可能用来描述一个ziplist,ziplist本身是一块连续的内存空间,ziplist内的node不保存前后指针,因为其连续内存的特性,只需要保存当前size和前一项size即可完成向前和向后寻址,提供和双项链表一致的操作。
hash
哈希表,很容易理解
但底层使用ziplist和dict两种结构进行存储。
- 节点数量大于 512(hash-max-ziplist-entries) 或所有字符串长度大于 64(hash-max-ziplistvalue),则使用 dict 实现;
- 节点数量小于等于 512 且有一个字符串长度小于 64,则使用 ziplist 实现;
ziplist存储时将field与value(就是KV)连着放在一起,提供更高的存储效率。在未序列化的情况下,该方式相比于string更节省内存。不过如果把对象的各个KV序列化为一体然后存储为string,也许占用空间还更小。
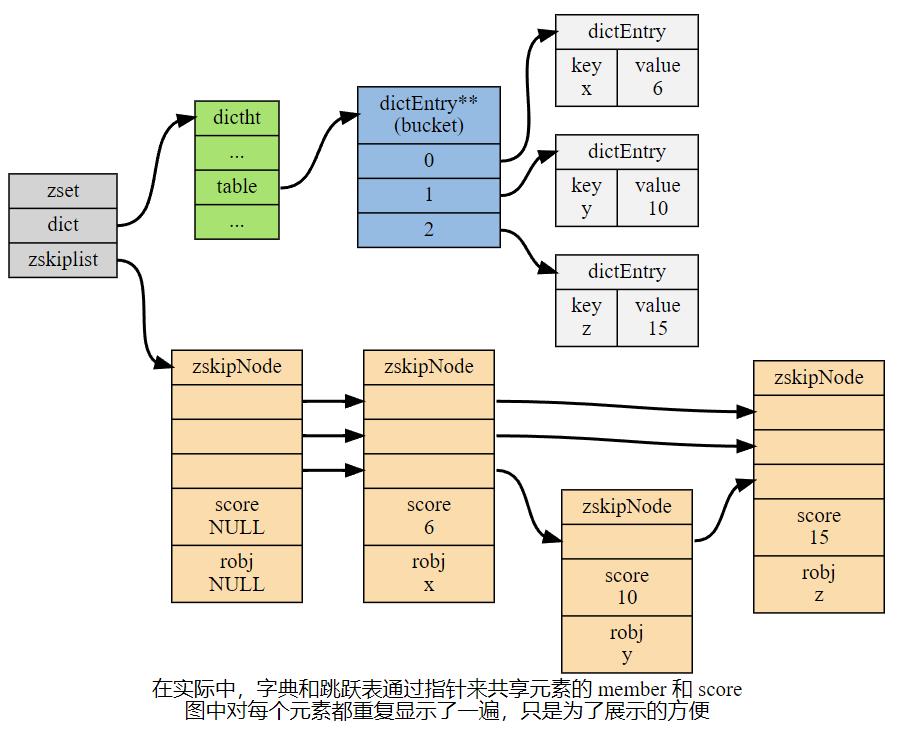
dict就是标准的哈希表实现,不过一个dict内部保存两个哈希表ht0和ht1,ht1用来进行rehash的中转。该表使用开链法解决hash冲突。一张引用自redisbook的图很清晰的说明了结构:
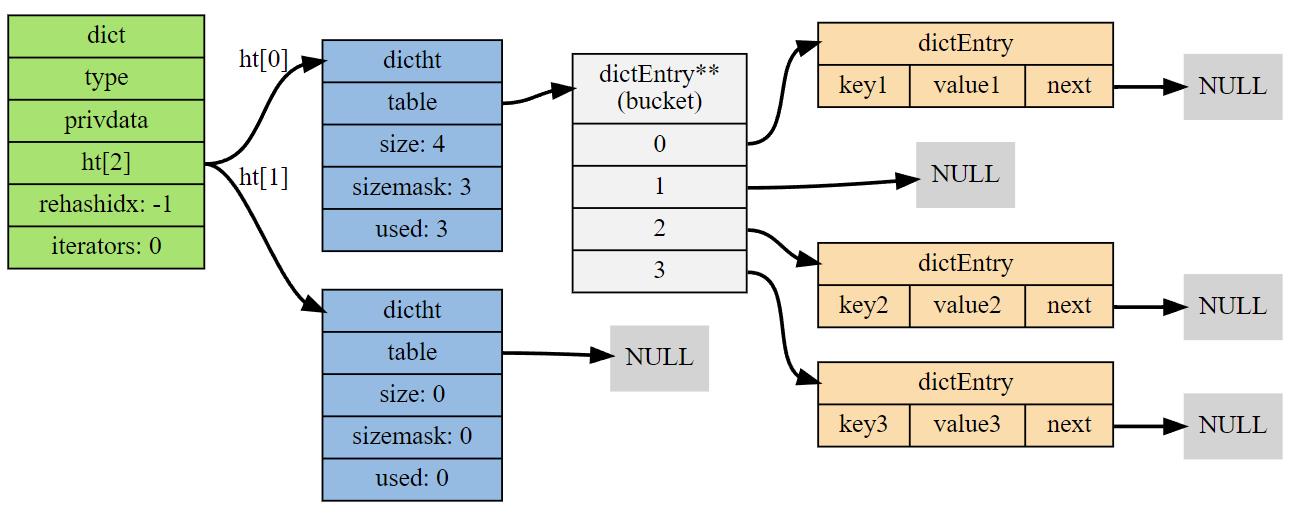
当rehash工作量太大时,需要使用渐进式rehash,此时不会发生
set
集合,不要求有序
- 元素都为整数且节点数量小于等于 512(set-max-intset-entries),则使用整数数组存储;
- 元素当中有一个不是整数或者节点数量大于 512,则使用字典存储;
类比hash内部,这里不再详细分析,字典编码Value为NULL即可
zset
有序的集合
- 节点数量大于 128或者有一个字符串长度大于64,则使用跳表(skiplist);
- 节点数量小于等于128(zset-max-ziplist-entries)且所有字符串长度小于等于64(zset-maxziplist-value),则使用 ziplist 存储;
ziplist编码
|<-- element 1 -->|<-- element 2 -->|<-- ....... -->|
+---------+---------+--------+---------+--------+---------+---------+---------+
| ZIPLIST | | | | | | | ZIPLIST |
| ENTRY | member1 | score1 | member2 | score2 | ... | ... | ENTRY |
| HEAD | | | | | | | END |
+---------+---------+--------+---------+--------+---------+---------+---------+
score1 <= score2 <= ...
ziplist 内连续的有序的保存entry
skiplist编码
/*
* 有序集
*/
typedef struct zset {
// 字典
dict *dict;
// 跳跃表
zskiplist *zsl;
} zset;
使用dict来检索,使用skiplist维持顺序
引用redisbook的图,说的很清晰:
协议与网络
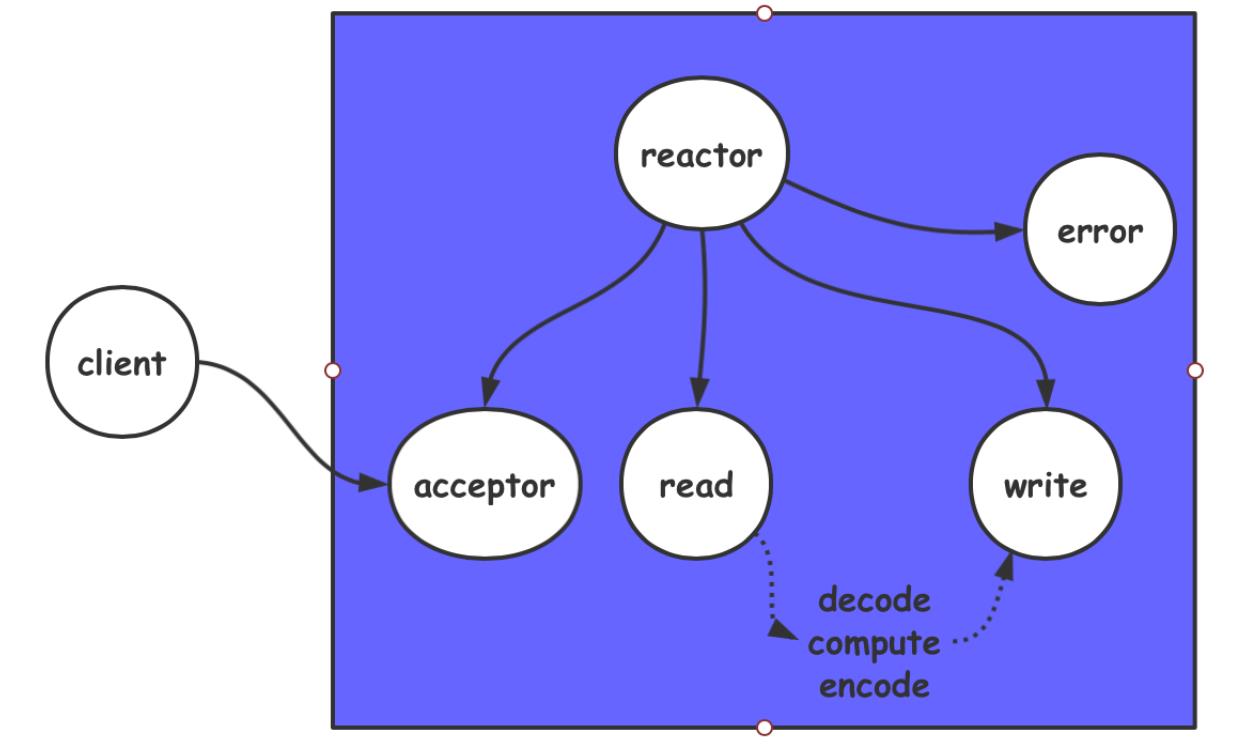
网络层
redis6.0 单reactor模型,并发处理连接,线程串行处理命令。
reactor管理触发的socket,调用其对应的callback(accept,recv or send),这里callback使用单线程串行处理
事务
MULTI 开启事务,事务执行过程中,单个命令是入队列操作,直到调用 EXEC 才会一起执行;
也可以使用DISCARD取消事务
WATCH 检测key的变动,若在事务执行中,key变动则取消事务,在事务开启前调用,乐观锁实现(cas), 若被取消则事务返回 nil。
lua 脚本
- lua 脚本实现原子性。
- redis中加载了一个lua虚拟机,用来执行redis lua脚本。redis lua 脚本的执行是原子性的,当某个脚本正在执行的时候,不会有其他命令或者脚本被执行。
- lua脚本当中的命令会直接修改数据状态。
Tips:如果项目中使用了lua脚本,不需要使用上面的事务命令。
发布订阅
为了支持消息的多播机制,redis引入了发布订阅模块。disque 消息队列
订阅
struct redisServer {
// ...
dict *pubsub_channels;
// ...
};
redisServer 中一项pubsub_channels的字典保存了订阅频道的信息。 字典的键为正在被订阅的频道, 而字典的值则是一个链表, 链表中保存了所有订阅这个频道的客户端。
发布
首先根据 channel 定位到字典的键, 然后将信息发送给字典值链表中的所有客户端。
订阅模式
一个发布的信息,与其发布频道相匹配的所有模式频道也会将这个信息发布给自己旗下的订阅用户。
struct redisServer {
// ...
list *pubsub_patterns;
// ...
};
这次是pubsub_patterns链表了,每个节点都有一个pubsubPattern结构
typedef struct pubsubPattern {
redisClient *client;
robj *pattern;
} pubsubPattern;
client 属性保存着订阅模式的客户端,而 pattern 属性则保存着被订阅的模式。
通过遍历整个 pubsub_patterns 链表,程序可以检查所有正在被订阅的模式,以及订阅这些模式的客户端。
发布到模式
PUBLISH 除了将 message 发送到所有订阅 channel 的客户端之外, 它还会将 channel 和 pubsub_patterns 中的模式进行对比, 如果 channel 和某个模式匹配的话, 那么也将 message 发送到订阅那个模式的客户端。
redis6.0 io多线程
redis6.0版本后添加的 io多线程主要解决redis协议的压缩以及解压缩的耗时问题;一般项目中不 需要开启;如果有大量并发请求,且返回数据包一般比较大的场景才有它的用武之地;
单线程
正常的redis单线程处理事件,但是其read write操作都需要经过内核栈,需要从内核的内存空间中取出或发送包,内核到用户内存空间的复制又涉及页表项的修改等。所以总的来说IO占用的CPU时间较多。如果这时引入多线程IO,有效利用多核可以进一步提升性能。
多线程实现
外部来看还是单线程的状态,这是因为多线程参考主线程的phase。只有主线程处于read phase,其他线程才做read操作,只有主线程处于write phase其他线程才做write。并且任务的分配也由主线程完成,每个thread维护一个任务队列(链表组织),主线程唤醒thread去执行任务,可以使用cond去唤醒。
redis扩展
Redis 通过对外提供一套 API 和一些数据类型,可以供开发者开发自己的模块并且加载到 redis 中。类似插件。在不侵入 redis 源码基础上,提供一种高效的扩展数据结构的方式,也可以用来实现原子操作。
入口函数
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int
argc);
// RedisModule_Init 应该要是第一个被调用的函数
static int RedisModule_Init(RedisModuleCtx *ctx, const char *name, int ver,
int apiver);
// RedisModule_CreateCommand 应该要是第二个被调用的函数
REDISMODULE_API int (*RedisModule_CreateCommand)(RedisModuleCtx *ctx, const
char *name, RedisModuleCmdFunc cmdfunc, const char *strflags, int firstkey,
int lastkey, int keystep);
// 回调函数
typedef int (*RedisModuleCmdFunc)(RedisModuleCtx *ctx, RedisModuleString
**argv, int argc);
RedisBloom
布隆过滤器,准确判断不存在的值
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
make
cp redisbloom.so /path/to
vi redis.conf
# loadmodules /path/to/redisbloom.so
具体使用直接看github
hyperloglog
少量内存下统计一个集合中唯一元素数量的近似值。
在Redis实现中,每个键只使用 12kb 进行计数,使用 16384 个桶子,每个桶子6bit,标准误差为0.8125% ,并且对可以计数的项目数没有限制,除非接近 个项目数(这似乎不太可能)
持久化
redis 的数据全部在内存中,如果突然宕机,数据就会全部丢失,因此需要持久化来保证 Redis 的数据不会因为故障而丢失,redis 重启的时候可以重新加载持久化文件来恢复数据;
三种方式:
-
aof (append only file)
-
rdb (Redis Database)
-
rdb + aof
AOF
可以认为是一系列的操作log,以协议文本的方式,将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件,以此达到记录数据库状态的目的。
同步命令到 AOF 文件的整个过程可以分为三个阶段:
- 命令传播:Redis 将执行完的命令、命令的参数、命令的参数个数等信息发送到 AOF 程序中。
- 缓存追加:AOF 程序根据接收到的命令数据,将命令转换为网络通讯协议的格式,然后将协议内容追加到服务器的 AOF 缓存中。
- 文件写入和保存:AOF 缓存中的内容被写入到 AOF 文件末尾,如果设定的 AOF 保存条件被满足的话, fsync 函数或者 fdatasync 函数会被调用,将写入的内容真正地保存到磁盘中。
保存模式
Redis 目前支持三种 AOF 保存模式,它们分别是:
- AOF_FSYNC_NO :不保存。
- AOF_FSYNC_EVERYSEC :每一秒钟保存一次。
- AOF_FSYNC_ALWAYS :每执行一个命令保存一次。
AOF 重写
AOF文件会积累变大,所以积累到一定量时,会创建一个新的 AOF 文件来代替原有的 AOF 文件, 新 AOF 文件和原有 AOF 文件保存的数据库状态完全一样, 但新 AOF 文件的体积小于等于原有 AOF 文件的体积。相当于对冗杂的指令进行简化,使最终结果一样就行。
重写在后台子进程中发生,子进程带有主进程的数据副本,使用子进程而不是线程,可以在避免锁的情况下,保证数据的安全性。
不过, 使用子进程也有一个问题需要解决: 因为子进程在进行 AOF 重写期间, 主进程还需要继续处理命令, 而新的命令可能对现有的数据进行修改, 这会让当前数据库的数据和重写后的 AOF 文件中的数据不一致。
为了解决这个问题, Redis 增加了一个 AOF 重写缓存, 这个缓存在 fork 出子进程之后开始启用, Redis 主进程在接到新的写命令之后, 除了会将这个写命令的协议内容追加到现有的 AOF 文件之外, 还会追加到这个缓存中。
重写完毕后会将缓存并入新的AOF文件中去。
RDB
可以认为是当前存储的内存映像or快照,将数据库的快照(snapshot)以二进制的方式保存到磁盘中。
核心方法:保存与载入
保存
rdbSave 函数负责将内存中的数据库数据以 RDB 格式保存到磁盘中, 如果 RDB 文件已存在, 那么新的 RDB 文件将替换已有的 RDB 文件。
在保存 RDB 文件期间, 主进程会被阻塞, 直到保存完成为止。 有两种方法:SAVE 和 BGSAVE SAVE: 会阻塞主进程开始保存RDB,直到保存完毕返回 BGSAVE: 会fork出子进程进行保存RDB,但直到保存完毕中间的一段数据有可能会丢失 SAVE与BGSAVE不能同时执行,且BGSAVE也不能与REWRITEAOF同时执行,这是因为创建俩进程来做这个事情效率太低 SAVE的时候AOF一样会写入,因为AOF写入又后台线程完成
载入
在载入期间, 服务器每载入 1000 个键就处理一次所有已到达的请求, 不过只有 PUBLISH 、 SUBSCRIBE 、 PSUBSCRIBE 、 UNSUBSCRIBE 、 PUNSUBSCRIBE 五个命令的请求会被正确地处理, 其他命令一律返回错误。 等到载入完成之后, 服务器才会开始正常处理所有命令。
Tips:发布与订阅功能和其他数据库功能是完全隔离的,前者不写入也不读取数据库,所以在服务器载入期间,订阅与发布功能仍然可以正常使用,而不必担心对载入数据的完整性产生影响。
RDB + AOF
因为RDB的保存过程较长可能会错过一些数据,所以在RDB进行保存的时候使用AOF缓存来记录保存时发生的写入操作,然后将AOF缓存持久化为AOF,通过AOF+RDB就可以完整的表述数据
主从复制
主要用来实现 redis 数据的可靠性。防止主 redis 所在磁盘损坏,造成数据永久丢失。
主从之间采用异步复制的方式。
集群
Redis cluster集群