之前一直很好奇,在超算里(或大规模的集群里),是怎么减少network传输的损耗的,最近项目中接触到了mecury这个rpc框架,他依赖于OFI、libfabric这个网络框架来做集群内的高性能网络传输。
OFI相比于普通的内核TCP/IP协议栈的优化思路与用户态协议栈有异曲同工之妙,准备好好写一下这篇笔记,先从内核里的TCP/IP协议栈的缺点开始,到优化思路与实现,再看看能不能学习一下ofi实现的trick。开个坑先,慢慢写。。
从缺点找灵感
TCP/IP 缺点
- 用于提供可靠性的header占用很多带宽
- 同步的话耗时,异步的话耗空间(内核里的缓冲区)拷贝也耗时
高性能的网络API应该是什么样的?
尽量少的内存拷贝
两点:
- 用户提供buffer,与协议栈用一个buffer
- 建立一个流量控制机制
异步操作
两种策略:
- 中断和信号,这种机制会打断正在运行的程序,evict CPU cache,而且一个随时能接受信号还不影响自己工作的程序就比较难开发
- 事件queue, 来了就进queue
Direct Hardware Access
主要两种思路:
- 越过kernel,直接与网卡的buffer交互(代表DPDK)
- 硬件软件配合来在用户空间共享同一块地址空间作为buffer(RDMA)
那应该怎么设计呢?
先抄来个需要的interface:
/* Notable socket function prototypes */
/* "control" functions */
int socket(int domain, int type, int protocol);
int bind(int socket, const struct sockaddr *addr, socklen_t addrlen);
int listen(int socket, int backlog);
int accept(int socket, struct sockaddr *addr, socklen_t *addrlen);
int connect(int socket, const struct sockaddr *addr, socklen_t addrlen);
int shutdown(int socket, int how);
int close(int socket);
/* "fast path" data operations - send only (receive calls not shown) */
ssize_t send(int socket, const void *buf, size_t len, int flags);
ssize_t sendto(int socket, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t sendmsg(int socket, const struct msghdr *msg, int flags);
ssize_t write(int socket, const void *buf, size_t count);
ssize_t writev(int socket, const struct iovec *iov, int iovcnt);
/* "indirect" data operations */
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
首先来看看这几类都有什么目标?
“control” functions : 这东西是用来控制的,一般调用次数一两次,不需要高性能。 “indirect” data operations: 这个东西虽然性能也重要的,但是跟操作系统调度带来的损耗相比,他的损耗直接被抹平
所以主要:
“fast path” data operations
这种操作是最需要改善的
更少的参数
很好理解,略
更少的LOOP和分支
在interface内部的实现中,尽量少的使用分支和loop
Command Formatting
网卡驱动程序与网卡交互的时候有formatting,如果这个格式控制可以由application插手,那可以做很多特定的优化,将网路通信的path搞得更确定,比如我知道我只和这个peer通信,那么我直接给包加个头,这个头会由网卡取到然后发送给peer。流程更少,性能更高。
Memory Footprint
减小内存占用:
举个例子:一个socket address:
/* IPv4 socket address - with typedefs removed */
struct sockaddr_in {
uint16_t sin_family; /* AF_INET */
uint16_t sin_port;
struct {
uint32_t sin_addr;
} in_addr;
};
这里面这个sin_family标识了协议栈,这个东西很多peer都一样,那直接让一样的用一个就行,能节省很多空间。
这只是个例子,为了说明节省内存的思路。
Communication Resources
首先,可以使用预发布缓冲区的思路,就是我不知道我这一次要接受多少的数据,我直接post一块4MB的缓冲区,作为一次接收的缓冲区,意思就是哪怕这一次传输只传了1KB(很多浪费),我也不管。那么消息和缓冲区就一一对应。
当然对大小不同的数据使用不同的通信协议也是很有必要的,因为他们对应的缓冲区的管理难度不同。
共享接收队列
为每一个address peer维护一个缓冲区块集合好像有点成本太高。而且有的通信频繁的peer会阻塞,而其他的buffer却一直空着,也不均衡。
现在考虑所有endpoint用一个缓冲区块集合,来请求的时候就从集合里分发一块。类似池的思路。
多接收缓冲区
多接收缓冲区是另一种思路:
它通过维护消息边界的方法,尝试重用每一块缓冲(那个4MB的),举个例子:一个1KB的消息到来,进入4MB的缓冲区内,剩下的将不会被浪费,而是给这1KB的数据加上头尾,区分边界,继续尝试利用4MB-1KB的空间接受更多的数据。
Optimal Hardware Allocation
控制硬件资源(网卡),一般来讲网卡有自己的控制程序,为了极致的性能,考虑暴露接口给用户来控制网卡行为。
Sharing Command Queues
将使用的共享接收队列暴露给应用程序,叫用户自己控制多个endpoint怎么使用共享队列。(不同endpoint可能有不同优先级之类的)
Multiple Queues
直接不用多个endpoint,用一个endpoint就行,这样address也就一个,充分利用网卡资源。
Ordering
顺序问题,如果要保证顺序,那显然问题会变复杂,性能会变差。
UDP是值得参考的,而且在local 网络内一般顺序是自动保证的,因为线都是自己连接的,可控程度很高。
Messages
与UDP不同的是,OFI的设计可以是很大的message(1GB)。
它将每一次发送都分成很小的块,比如要发送一个64KB的块和一个4KB的块,接收端有64KB和4KB俩buffer,如果乱序,64KB的就被截断。但是无所谓,因为每次发送1KB的小块,后面在组装起来。
Data
数据顺序就比较重要,尤其是数据在更新同一个缓冲区的情况,顺序更应该保证。
但同一个message内的数据顺序就不那么重要,除非有的机制用到了最后一个数据块来标识message结束,那就需要保证一个message内的数据顺序。
Completions
操作的完成顺序,这个不知道有啥优化的点。。
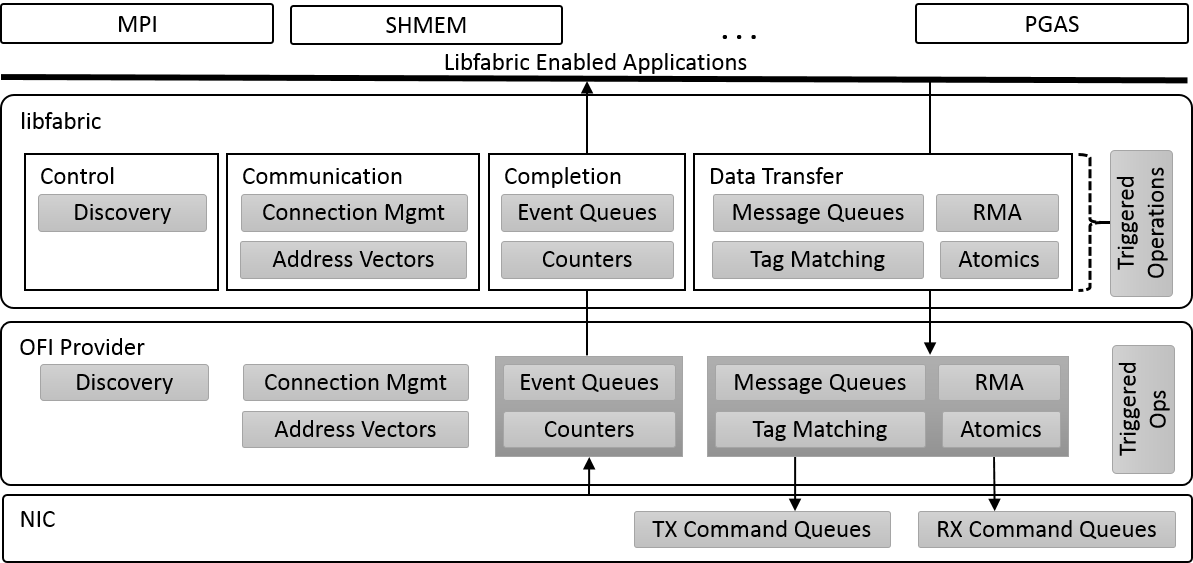
OFI Architecture