
原文:System Software for Persistent Memory
这篇文章分析了NVM出现的情况下,软件层面(主要是内存和文件系统)的一些变革和适配。14年的文章了,intel的人参与,显然在傲腾研发的时候发出来的。
后面的nova是借鉴了这里的思路的,堆砖砌瓦,总觉得这种知识的传承和发掘很有趣。。。
这篇文章搞了个PMFS,发掘了fs在NVM上的优化思路。(细粒度logging和大规模的页IO)
背景
先来回顾一下PM发展,从一开始将NAND flash与DRAM混合使用(NVDIMM),掉电时放入NAND flash,上电再从NAND flash中加载出来到DRAM中。(电池+NAND Flash+DRAM)这样的做法,但是因为受限于NAND,这玩意还是只能block addressable。想要byte-addressable还得看NVM(PCM等做法)。对于PM主要两种思路:1. 扩展虚拟内存管理器来将PM当内存用2. 把PM当块设备用(FS里,ext4的做法)3.直接做个文件系统,跳出块设备的层来管理PM。
于是就有了PMFS:这是个POSIX semantic的fs,有一些针对NVM的特殊优化。
PMFS:
- API完善(POSIX-compliant file system interface),所以向后兼容老的应用程序。
- 轻量级文件系统,绕过VFS的块设备层,避免了繁杂耗时的内核发生的拷贝(page cache),过程调用等
- 优化的mmap,绕过page cache(需要先从disk->SSD拷贝到memory->DRAM),这是为了加速,但在NVM里就不需要,直接从NVM映射用户空间页表就可以,应用需要的时候直接通过虚拟内存就能寻址到
. PMFS also implements other features, such as transparent large page support [18], to further optimize memory-mapped I/O. —有待研究
挑战:
- 现在的内存管理器把PM作为一个memory用,因为cache(WB)的存在,写回是异步的,这个memory并不会及时更新,比如cache还未写回PM,就掉电,那数据还是要丢失,durable和reliability就无法保证。所以需要一个原语来完成这种强制写回。PM write barrier or pm_wbarrier这是一个硬件实现.
- 为了性能,PM被PMFS直接整个映射到内核地址空间,这就带来了stray writes的问题(就是kernel里出bug的话–一般是内核驱动程序出错,指针写到我PM的这一块内核地址空间去了,发生了脏写)。一个解决办法是平时在cpu的页表里把PM设置为只读,需要写的时候先改成写,写完再改成只读。但你这样搞,来回变页表,TLB要一直更新 global TLB shootdowns,cost很大。所以intel的人实现了个utilize processor write protection control to implement uninterruptible, temporal, write windows(回头看看是啥)。
- 测试可靠性(主要是consistency),Intel的人开发了个东西:For PMFS validation, we use a hypervisorbased validation tool that uses record-replay to simulate and test for ordering and durability failures in PM software (§3.5)
- mmap直接用过于底层,PMLib这个东西封装了一下mmap,提供给app调用,更方便。
Architecture
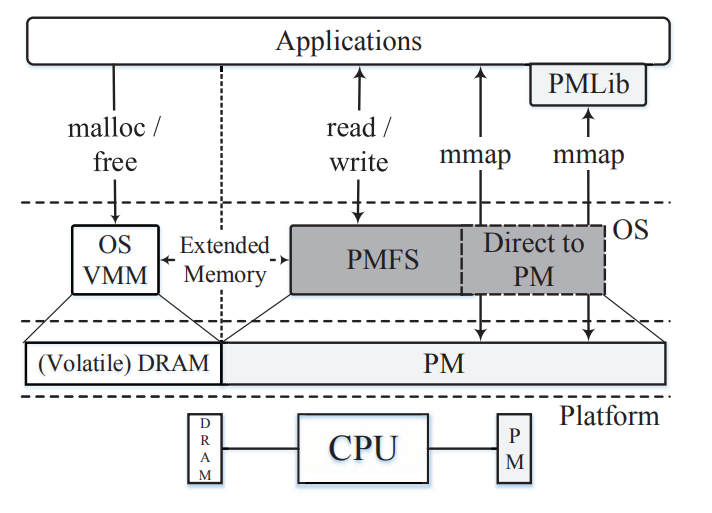
几种之前的方法来保证一致性和durable:
- mapping PM as write-through —– 带宽有限,代价太高
- limiting PM writes to use non-temporal store instructions to bypass the CPU caches ———suffer from performance issues for partial cacheline writes, further discouraging general use 大意就是用起来不具有普适性–不用cache还是不行,cache毕竟快
- a new caching architecture for epoch based ordering(这个东西有点意思 要看看)【Better I/O Through Byte-Addressable, Persistent Memory】 ——- require significant hardware modifications, such as tagged cachelines and complex write-back eviction policies。 Such hardware mechanisms would involve non-trivial changes to cache and memory controllers, especially for micro-architectures with distributed cache hierarchies. 这个策略要硬件修改还要配套协议,太复杂,在一个分布式环境下,要对所有node都修改,也是挺麻烦的non-trivial
分析了一波,还是用WB策略加显示的强制cache写到PM上靠谱。但这种实现问题很显然:durable?掉电,会丢失数据。假设只用:clflush + sfence , it does not guarantee that modified data actually reached the durability point,这是为啥呢,内存控制器和处理器的锅:第一硬件的写并不是一次性完成的,内存管理单元把写请求入队就返回并认为完成了,实际他可能还在内存控制器(或processor)那里排队呢。第二内存控制器为了维护处理器的内存访问模型,很可能将数据缓存在一个buffer(就是写缓冲区)里,等满足访问模型要求的数据顺序保证了之后再处理。 对于一般的内存架构(DRAM SSD),因为DRAM本来就是volatile的,返回写成功代表写入DRAM,所以开发人员是知道的因为写入DRAM还是会掉电丢失,就通过别的方法想办法保持durable,但现在PM在DRAM的位置替代了它,当我们以为返回成功也就是数据写入我们认为数据写入PM(durable了时),其实他可能只是被processor或memory controller放到写缓冲区去了,也就是没写到PM,相当于骗了我们。 这就是个大问题,所以clflush + sfence还不够,得搞个新的原语。
pm_wbarrier这个硬件原语来了,这个原语有俩平行的层次:
- on-demand variant(可以理解为主动调用生效)同步的,主动调用来保证durable。
- lazy variant(被动生效)异步的,掉电前自动完成保护操作。
当然这篇文章用的是on-demand variant
使用优化的clflush,提升性能(weaker ordering on cache write back operations.然后用sfence来保证ordering),相比于之前的clflush(可以看看之前的为啥差:【Implications of CPU Caching on Byte-addressable Non-Volatile Memory Programming】【Mnemosyne: Lightweight Persistent Memory】)
按顺序来:
- clflush
- sfence
- pm_wbarrier
关于编程难度:多用库
对于特定的流式写操作:PMFS使用non-temporal stores
磨损问题: 还是让硬件来支持吧,软件支持太复杂了。
Design&Implementation
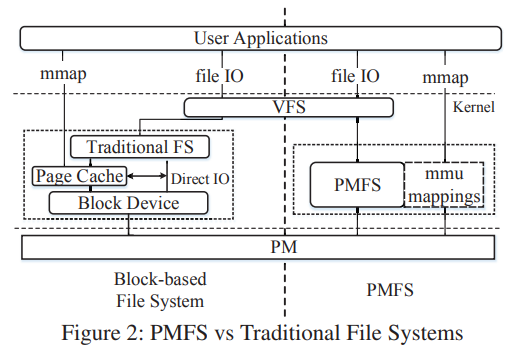
看眼图就知道了,这是一个对比。关键是,怎么实现的:
这是很大的一部分,三个层面来说:
Optimizations for memory-mapped I/O
首先:基于PM和CPU的micro架构来设计
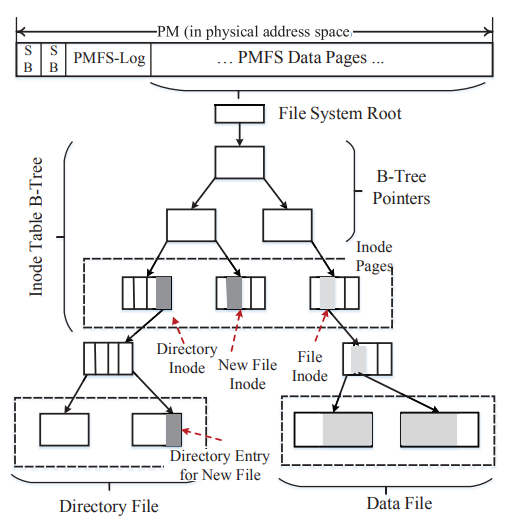
上图可知,metadata用B-树组织(best for sparse data),PM里SB后面紧跟着LOG。然后是DataPage。LOG空间有限自然要定期清除。
B-tree不止组织元数据,还组织file datapage。
- Allocator:
extent-based allocations(ext4) 组织数据的最小单位可以自由的extent到各种大小。
indirect block-based(ext2)
PMFS是page-based的,page大小支持各种processor的microarch(4KB, 2MB,1GB) 为了支持Transparent hugepage support( works by scanning memory mappings in the background (via the “ khugepaged ” kernel thread), attempting to find or create (by moving memory around) contiguous 2MB ranges of 4KB mappings, that can be replaced with a single hugepage)
目前PMFS的内存分配和管理机制还是比较朴素的,就是把page连续放在一起来避免fragment。
- Memory-mapped I/O (mmap):
mmap直接把PM映射到user 的address space,user 可以直接访问PM。
用的是最大size的page来做映射,这样page fault少,TLBmiss也少但粗粒度的page也有缺点(internal fragmentation)。 大的page产生的page table也小,page table在DRAM上,DRAM空间少于PM,所以就很合理。
默认page 大小4K,可以两种方法修改:
- mount的时候确定,对于fixed or similar的size工作比较合适
- Using existing storage interfaces to provide file size hints, communicate this to PMFS using either fallocate (to allocate immediately) or ftruncate (to allocate lazily). These hints cause PMFS to use 1GB pages instead of 4KB pages for the file’s data nodes.需要给linux GNU 的fallocate加一点功能来支持大页。
最后,只有mmap的使用不是COW的(MAP_SHARED或只读区域),才能使用大页,否则都是4K。
Consistency
. In PMFS, every system call to the file system is an atomic operation
而用mmap来做的区域就需要程序员自己保证consistency了。
目前主要就三种技术:
- copy-onwrite (CoW)
- journaling (or logging)
- and logstructured updates
COW()和LS(WAL)都有写放大的问题,metadata的修改粒度很细,对于metadata用journaling比较合适。
以减小写的量和同步的次数(pm_wbarrier的次数)来衡量cost。
主要结论是logging at cacheline or 64-byte granularity最好。
PMFS里用的是atomic in-place updates and finegrained logging来实现metadata的update, COW来做file data的update,三合一
- journaling for metadata :
主要有undo和redo两个实现方式。各有优劣:
undo是基于steal的,也就是uncommitted的操作也会持久化,就需要基于undo log撤销一下。在PMFS里实现就需要在transcation里的每一个log entry之间使用同步原语确保undo log持久化。
redo是基于unforce的,就是committed的操作不需要立即持久化,可能被缓存等,那么恢复时就需要基于redo来重新committ一下。在PMFS里实现只需要在在transaction committed之前(准确的说是最后一个committed log之前)确保redo log持久化,这里需要两次同步原语。但有一个问题是,如果很多事务都没被持久化,比如现在有4个事务已经提交了但是都没有持久化,那在PM里就无法体现事务的修改,就需要去redo log里找信息,也就是说,所有对data的read操作都需要先确保data是最新的,对于journaling来说也就是要先从PM里复制出来,再对copy的data redo log过一遍,再做读操作。如果积累的未提交事务较多,后续事务里的read操作就产生很多redo的load。尤其是当这个data粒度很小,需要redo的log可能很多,因为PMFS用journaling做metadata的consistency,metadata很小,那就不用redo。
虽然用了undo,但是在log很多但其中涉及修改的很少的时候,redo的同步开销还是导致性价比太低。作者说日后会分析。
这东西叫做PMFS-Log符合undo语义,放张图看看,这图后面分析实现的时候还会用:
journaling也不是一直用的,PMFS尽量使用atomic in-place updates操作能用的小数据操作,这样负担比较小,这个东西是基于processor的功能。
- Atomic in-place updates
PMFS的64,16bit原子操作有自己的优化:
- 8-byte atomic updates
用于update an inode’s access time on a file read.
处理器都支持这个操作应该是CAS。
- 16-byte atomic updates:
处理器using cmpxchg16b instruction (with LOCK prefix)来支持
用处比较多,如: atomic update of an inode’s size and modification time when appending to a file.
- 64-byte (cacheline) atomic updates:
The processor also supports atomic cacheline (64-byte) writes if Restricted Transactional Memory (RTM) is available 处理器得支持RTM这个东西,就能支持64位原子操作。 步骤是:用XBEGIN开启RTM事务然后修改然后用XEND关闭RTM事务。后续的clflush会把cache刷回PM。处理器不支持RTM的话PMFS就用上面的fine-grained logging来搞了。
PMFSLog: fixed-size circular buffer 固定大小的换新缓冲区,data的图里也能看出来
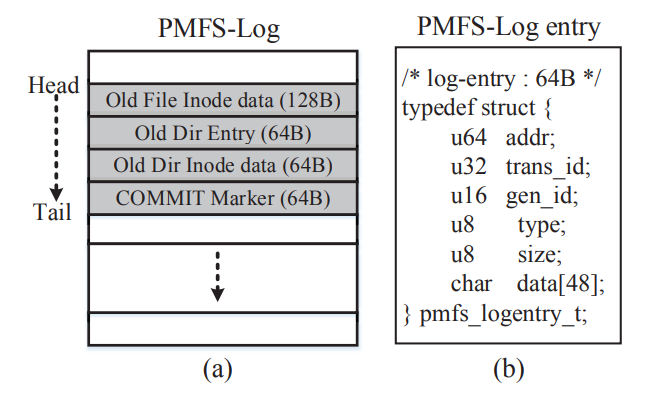
trans_id:这个东西标识了这个log所属的事务,因为每个事务都有自己专属的trans_id
gen_id: 需要和metadata的gen_id相同,不然就标识着这个log无效,系统恢复时判断log就看这个,系统恢复用过log之后就会把log的gen_id增加(就相当于无效化这个log了,环形的覆盖时也会给gen_id加一)
log有效性: 有一个情形:log的有效位被设置,但是log的内容还没来得及设置就掉电了。那么这个log就出现了错误。
怎么解决呢?很朴素:就是确保log的内容先持久化到PM里,再确保log的有效位持久化到PM里,维持这个顺序就行。
可是有两点会影响这个顺序的保持:1. CPU的reorder write 2. compiler的reorder , 编译器的很好解决,只需要加个instruct就行, CPU的话就比较巧妙,PMFS用的LOG大小为64byte( fix the size of log entries to a single (aligned)cacheline), 利用CPU不会reorder一个cache line里的写顺序的特性,整个log的写都在一个cache line里,因为整个log被fix to a single (aligned)cacheline了,64byte在这里只是因为目前用的CPU cache line是64byte,重要的是要和cache line一样而不是64。这样的话,gen_id这个用来标记有效的成员就可以确保被最后一个写入了。
当然还有一些其他的方法来保证log有效:using a checksum in the log entry header【 In Proceedings of the Twentieth ACM Symposium on Operating Systems Principles】 or tornbit RAWL【 In Proceedings of the Sixteenth International Conference on Architectural Support for Programming Languages and Operating Systems】,回头可以研究一下具体是啥,再回来补上
看log的图,左侧:顺序就是首先写log(这个log在data字段里记录下old的值是什么,用于undo恢复旧值,如果不记肯定没法恢复)并持久化它,然后正式修改PM里的metadata,重复这个过程知道修改操作都搞完,最后需要一个commit的log,在将commit的log放进去之前需要先用同步原语确保cache里的metadata都写进PM(覆盖旧的值),然后提交committed的log并持久化他,这就代表着这个事务或原子操作结束了。
注意到需要记录旧的data,这就是undo+journaling,如果data太大都要复制,那当然overhead也大。
pm_wbarrier这个同步原语,如果能减少,性能肯定更好。这就要借助这个. A log cleaner thread,这个线程用于清理已经提交的事务相关的log,它的行为是先pm_wbarrier确保log事务真的提交(cache里的东西真的写入PM),然后修正head,让head掠过提交的log entry。这个线程是异步的,那既然他也要调用pm_wbarrier,那就干脆在commitlog写入之后就别再调用pm_wbarrier了,这样能提升性能。但是还是有一点点可能导致已经被commit的数据在重启后被undo log rollback,因为实际上commit log entry并没有进PM,恢复机制就不知道是不是真的已经commit了,只知道undolog里这些log entry的后面没commit log entry,他就会undo之前的log,就其实是把PM里已经完成修改的data又改回上一个版本了。
- Cow for file data:
大数据量操作使用COW机制来确保一致性,
数据会在元数据之前被持久化。(一致性还可以更强,比如一起持久化)( same as the guarantee provided by ext3 ext4 in ordered data mode.)
问题是,如果我用huge page(1GB),即使我只修改了几MB,我也需要copy整个1GB的page,这么严重的写放大也需要解决,但这个作者说后面再解决。。
- 恢复机制
在mount的时候检查log,取出uncommitted的log(其实就是事务里一些没有用commit log entry标记结尾的log entries),undo他们,当然实际上committed的log也会被取出来(看gen_id取出有效的),还会构造出committed和uncommitted的log的俩list,然后把committed的list丢掉。。。
- Consistency of Allocator:
首先得知道什么是allocator structure,它就是管理你分配空间的数据结构方便我们快速找到我们文件系统管理的空间,因为在文件系统里free和alloc太多(指频次太高),如果都要在log内记录消耗太大,干脆直接在DRAM里记录这个东西,PMFS里就是freelists,通过一个节点能找到一个inode(用于free和alloc时)(NOVA里radix tree也是这么做的,用radix tree来快速找到inode log),宕机的话。在下次启动时直接扫描PM里的那个B-树来恢复这个allocator structure。正常unmount就在末尾将这个allocator structure持久化到internal的一个node上(还是在那个B-树里),下次启动直接copy过来继续用。
Write Protection
Protect PM from stray writes.
看一下这个表格,列是操作的人,行是被操作的数据所有者。
- user 操作 user 数据
这个进程的地址空间自动就隔离了。
- user 操作 kernel 数据
进程能访问到的地址空间权限控制。
- kernel操作user的数据
Supervisor Mode Access Prevention 是一个处理器的机制。激活他就能防止kernel操作user的数据。
这个是必要的,因为mmap的使用。??。。。
- kernel 操作 kernel的数据
多个OS组件操作同一片内核空间,这个问题变得很复杂。。。
但是在这里只有个PMFS能操作PM,那就简单多了。
首先来看如果加一个权限位进data,那么会发生什么: 权限会来回变,TLB要不停的换页项,产生TLB shotdown,with high overhead
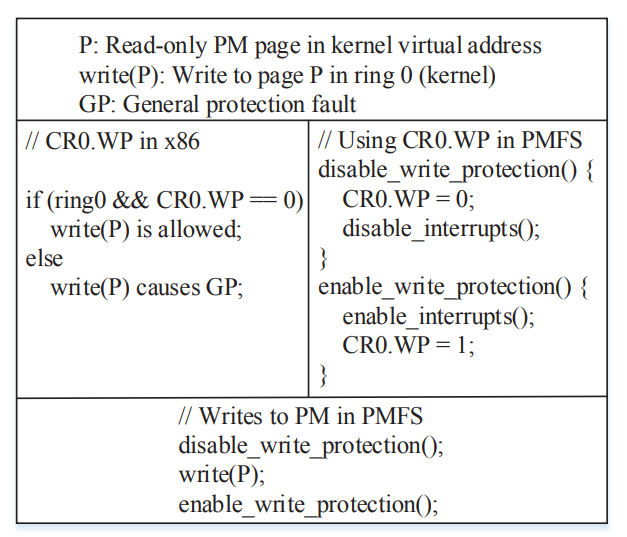
就按这张图这么搞,这张图应该从下往上看,顺序下右左。
当然有一个前提:PMFS首先默认整个PM是只读的,当需要修改的时候再改成可写然后修改然后再改回只读。
修改的流程就是上面那张图了。
CR0.WP 是处理器提供的一个写保护机制,修改它可以修改处理器的写的能力:x86里的机制
if (ring0 && CR0.WP == 0)
write(P) is allowed;
else
write(P) causes GP;
设想如果在修改可写和只读的过程中被异步中断打断,那就G了。所以需要开关中断:看途中右边有disable_interrupts();
这种方法就没改data,所以就很好没有TLB shotdown
有一些比较牛逼的处理器( Itanium)有诸如processor’s protection key registers (PKRs)这样的东西,并且在TLB里和写保护有关的tag。这种也是借助了其他的资源,没改data所以也没TLB shotdown
Implementation
- interface
首先, uses and extends the eXecute In Place (XIP) interface in the Linux kernel.使用和扩展了XIP,XIP是一个linux内核里的用于在PM上直接执行文件的接口(正常都是在DRAM上,考虑正常的一个spawn流程:fork进程解析ELF文件并将对应内容放到process的address的各个area(text,data。。。。这就是在DRAM上了),然后修改eip等寄存器,CPU就开始运行这个可执行文件了)。XIP直接就提供了一些VFS的回调函数,这些函数帮助我们跨过page cache和块设备层。也就是说PM不被识别为块设备,他的byte-addressable能力就能被发掘出来。(就是VFS的read,open等我们可以自己去写,然后注册到这个callback里去,PMFS就是xip_file_read, xip_file_write, xip_file_mmap替换了read,write,mmap)这些callback。XIP还有个callback需要PMFS实现并注册:get_xip_mem,这玩意是用来做PM上虚拟物理地址转换的。
同时,直接将PM映射到用户地址空间,也需要实现缺页函数。基于xip_file_fault来实现,并拓展huge page的支持。
还有个问题:页表太大(项太多),mount消耗时间太多。
因为PM只有PMFS,对PM的所有页都要建立页表项,不像普通的DRAM,第一DRAM不大,第二不需要所有页表项都在页表里,也放不下,需要的时候置换就行。PM同时作为主要存储和临时存储一般都比较大:256GB都不算大,但256GB下mount time和pagetable cost都很大了,所以直接实现个ioremap_hpage替代原本的ioremap用最大的page(1G)去建表,当然1G只针对内核地址空间,因为内核基本上就是固定的(与slab固定的各种unit有异曲同工之妙)。普通的地址空间当然还是可以用小的page的,况且在一开始也没用户进程,都是内核进程,那么关于页表的开销就被分散到后面的操作中,不会堆积在mount的时候,mount的时候大都是内核相关操作。
- procedure
describe a few common file system operations in PMFS.
- 创建
开启新事务并在PMFS-Log里分配需要的log entry。 -> 先从DRAM里的freelist拿到inode并初始化,然后log一下这个操作(共消耗掉俩log entry) -> 然后去B-树里找一个新的叶子节点作为directory entry(VFS的dentry)让他指向file inode,这里只消耗一个log entry -> 修改directory inode的属性(modification time),log一下,这里也要一个log entry -> 写个commit log收尾代表事务完成
- 写
首先,如果写的量比较小,不需要给file分配新页,那就直接COW机制写到file的data末尾然后atomic机制更新file inode的size and modification time。
如果需要分配新页:
开启事务,一样的先分配log entry, 分配页然后写数据到PM里(用 non-temporal store写,就是那个用于流的)。最后log和更新inode的B-树指针,让他加一个指向新分配的页,同时modification time这个元数据也需要更新。最后commit log entry收尾。
- 删除
inode的引用清零就开始删除inode,否则删除文件就是inode的ref减一。VFS会用一个callback来实施inode删除操作。
free inode就两步骤: 1. 修改inode的一些属性 2. 还给DRAM里的freelist
修改inode属性可以用64位的原子操作来做(如果有RTM的话),没RTM就用细粒度journaling做。操作涉及file inode和他的directory inode。
将inode还给DRAM里的freelist这个操作不需要保证,因为就算因为掉电没还进去,下次restart的时候freelists重建也需要扫描B-树来重建。
可能有用的tips:
Non-temporal in this context means the data will not be reused soon, so there is no reason to cache it. These non-temporal write operations do not read a cache line and then modify it; instead, the new content is directly written to memory.