
原文:Let’s Talk About Storage & Recovery Methods for Non-Volatile Memory Database Systems
cmu几个大佬在16年的文章,主要讨论的是完全的NVM下的优化,偏向于应用allocator而非FS,当然他也模糊了两者之间的概念,得益于NVM的nonvolatile,allocator也能实现naming,使用固定指针存到固定位置就行(FS里当然是地址开始处由SB提供信息了)。
background
OLTP的增多,简单就是数据增删改增多。所以需要优化DBMS。但是DBMS一直以来都在权衡VM(volatile memory)和NVM(non-volatile memory),因为他们自身的特性。DRAM作为VM可以按字节寻址,具有很高的读写性能,SSD/HDD等NVM只能按block寻址,随机写的性能也很差,一般都需要利用其顺序写速度快的特性来做优化(LSM in leveldb/rocksdb)。这里有一点:server里40%的能源都被flash DRAM用掉,DRAM需要一直刷新,即使这片数据不用也要刷新,不刷新就消失了。而SSD/HDD这些的缺点就不用说了,很慢,且写放大读放大都存在。
NVM是个概念,有一系列的具体实现技术,他就是兼具DRAM的性能和寻址又掉电保留数据。目前的DBMS都没有好好利用这个东西:
磁盘型DBMS如mysql orcal在内存中有一个cache,积累一下然后去顺序的以block写入磁盘,内存型DBMS如redis voltdb都有自己的持久化策略来缓和DRAM的易失性。这些多余的组件在NVM中都没必要。
这篇文章是讲一种只使用NVM的情况下的DBMS,不是DRAM和NVM混合架构也不是只用NVM做log(nova就有点这个意思)。
说一下模拟:
使用的是intel的一个工具,有一个microcode,他会用dram模拟nvm,当nvm需要停顿的时候就让cpustall。( The microcode estimates the additional cycles that the CPU would have to wait if DRAM is replaced by slower NVM and then stalls the CPU for those cycles. )
直接用libnuma来提供malloc,然后用fence来确保数据不会在cache中停留而是直接进入NVM。 文件系统也有对应的api,一个基于byte-addressable的FS。当然IO还是要过VFS tip:基于mmap可以不过VFS,特殊的mmap甚至可以掠过kernel里的page cache直接写数据到disk(NVMM)进一步加快速度。
这里用memory allocator,但是restart的时候不好找到数据,文件系统有superblock可以找到inode数据结构获取文件目录结构信息,memory没办法。所以改进一下:NVM-aware Memory Allocator
- 虚拟内存到NVM的映射是固定的,基于此保存指向这个地址的pointer,每次重启拿到这个pointer就可以获取到之前的数据信息。
- 避免数据在cache中停留引发的不一致,依次使用clflush将cache中的data写回数据,再用SFENCE确保clflush在这里完成(对所有processor可见,因为你现在把cache刷回去了那你得让cache刷回到所有proccsor,cache分级的,每个processor都有自己的呢,我理解实现上把cacheline置为steal就可以了),之后提交事务,这就是sync原语。
参照
三个存储引擎类型: (1) inplace updates engine, (2) copy-on-write updates engine, and (3) log-structured updates engine
从两部分来描述: 1. 事务怎么样作用 2. 怎么处理crash
当然这些都是没针对NVM优化过的
In-Place Updates Engine
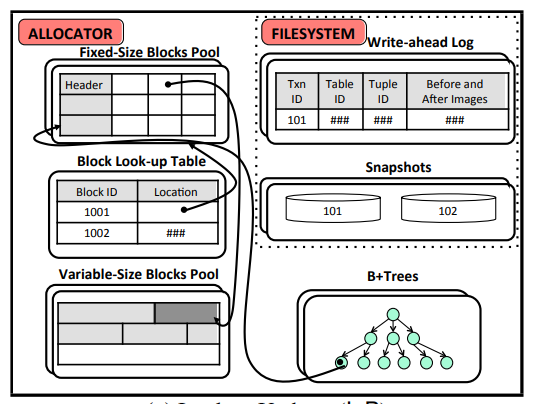
像VoltDB 这样的内存型数据库,直接在原位置更新数据没有buffer pool。
Block Pool分两种,一种定长一种变长,block大于8Byte就用变长的pool
还有一个Block lookup table用于找到block,对于变长的block,先通过Block lookup table在定长pool里找到其在变长Pool里的地址,然后再进变长pool找到真正的block
一般使用WAL(write ahead log)来在事务change前记录信息: the transaction identifier, the table modified, the tuple identifier, and the before/after tuple images depending on the operation
ARIES是比较有名的协议,他会定期做checkpoint也就是snapshot,每次恢复使用最新的checkpoint结合WAL里的commit的log来将DB恢复到断开之前的状态。
Copy-on-Write Updates Engine
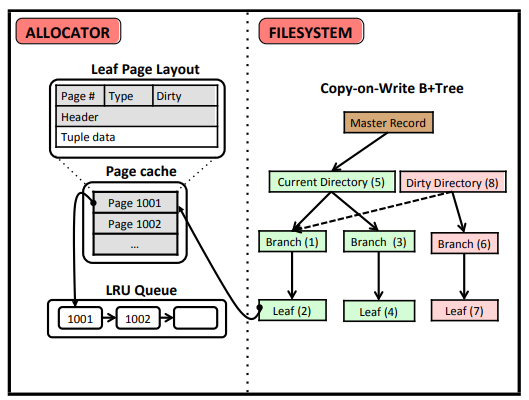
page cache加速查找,LRU来更新cache,最小单位是leaf,结构在leaf page layout里。
需要修改时,复制整个directory(LMDB’s copy-on-write B+trees使用特殊技巧,只复制从leaf到root路径上的nodes,其他nodes由dirty directory和current directory共享)。
复制完出现dirty directory之后开始修改,分两步:
- 在dirty directory上修改,指向新的tuple
- 事务commit之后,将master record指向dirty directory这时dirty就变成current了
master record是持久化在文件里的,他在某个特殊offset处。
这种设计存在写放大(总是要复制,写新的,再丢掉旧的),对NVM来说磨损太大。但他恢复时直接用旧的就行,因为旧的里肯定是commit过的数据,
Log-structured Updates Engine
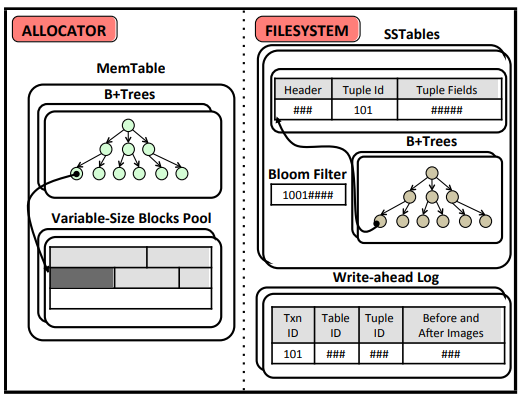
典型的:leveldb和他的“子集”rocksdb
放个leveldb的arch省个事。。
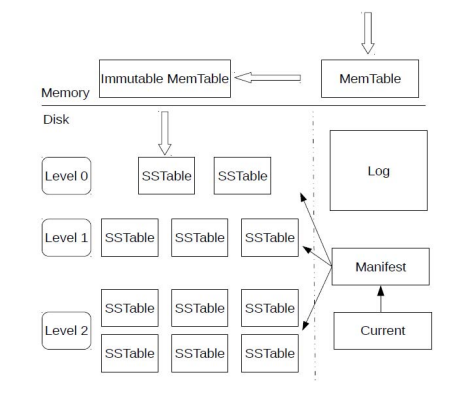
memtable到达指定大小就开始打包成为level0的一部分去持久化
各级level数量到达指定大小就开始打包向下一级迁移(compaction)
这一设计有利于顺序写,但是存在读放大,因为根据key找目标在哪一个sst就很可能需要好几次,这个是比较暴力的,用bloom filter可以快速排除sst但是还是得去触发到FS的IO操作没法在一次读操作里完成。
针对NVM的优化版本
In-Place Updates Engine
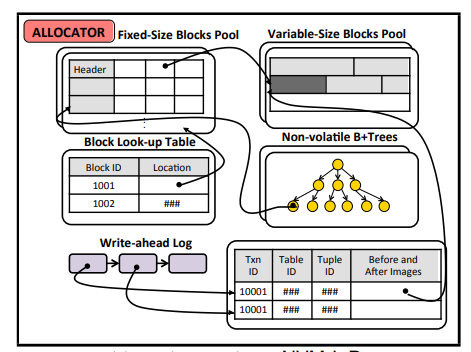
- NV的B+树存储索引,restart的时候不用再重建
- WAL中的log只需要保存指针,不需要保存一大块的数据tuple image,因为指针指向的数据就存储在NVM中,不会因掉电失去。
显然需要先写WAL再写data才能保证事务。
且log可以是一个链表,因为随机写的效率不再是问题。
Copy-on-Write Updates Engine
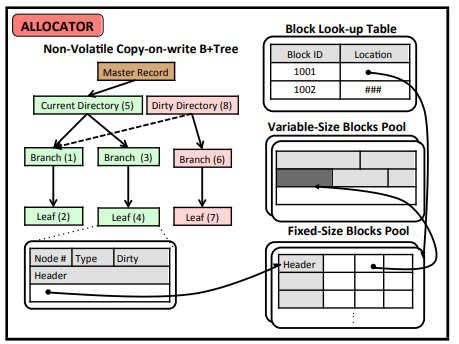
使用了非易失性的copy-on-write B+tree
直接持久化拷贝后的tuple副本其实就是拷贝到NVM中,并且在The dirty directory中保存非易失性指针-》也是在nvm中
用更轻量级的持久化机制来持久化copy-on-write B+tree中的更新操作
Log-structured Updates Engine
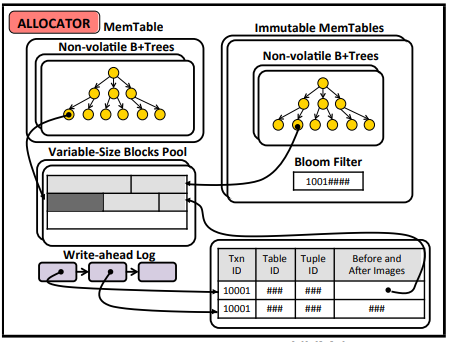
相比于之前使用sst还要分层来增加顺序性(sst)和减少读放大(compaction和分层),现在直接不需要sst,所有到了一定大小的memtable直接设置一个不可变位,变成immutable memtable就行,这些immutable memtable也可以再进行compaction的,同样每一个immutable memtable也有自己的bloom filter。 注意到memtable也在NVM中,那他就是非易失的,这就很像steal语义,uncommited的tuple被持久化了,那就需要再restart的时候吧这个uncommited的undo掉,所以这里的log是undolog。 且因为memtable本来就持久化在NVM中,不需要对他进行重建。